[Avg. reading time: 16 minutes]
Parquet
Parquet is a columnar storage file format designed for big data analytics.
- Optimized for reading large datasets
- Works extremely well with engines like Spark, Hive, DuckDB, Athena
- Best suited for WORM workloads (Write Once, Read Many)
Why Parquet Exists
Most analytics questions look like this:
- Total sales per country
- Total T-Shirts sold
- Revenue for UK customers
These queries do not need all columns.
Row-based formats still scan everything.
Parquet does not.
Row-Based Storage (CSV, JSON)
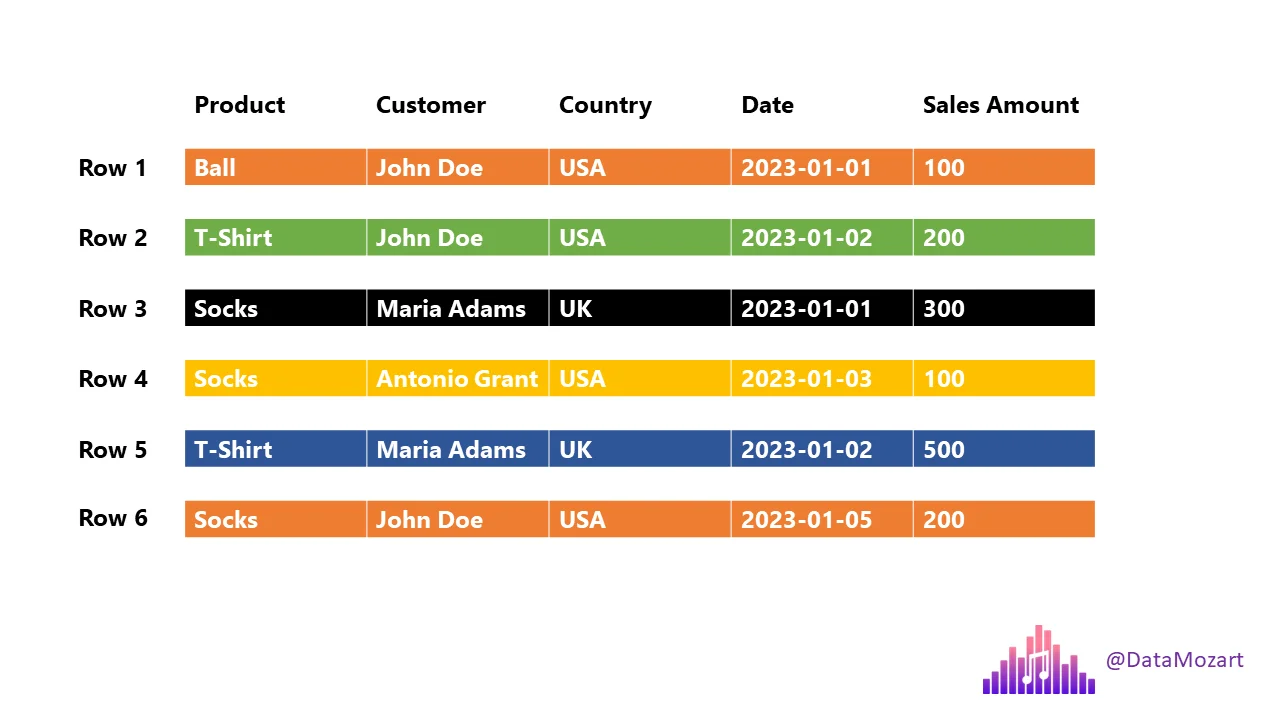
If you ask:
Total T-Shirts sold or Customers from UK
The engine must scan every column of every row.
This is slow at scale.
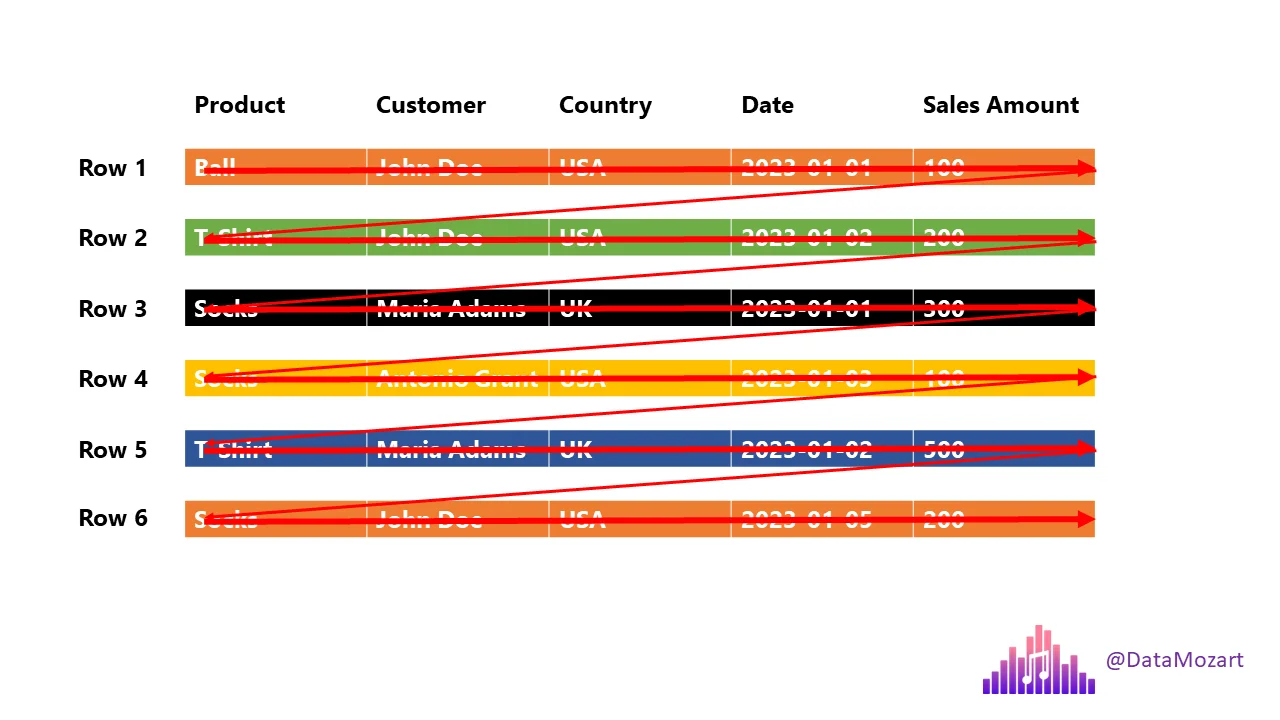
Columnar Storage (Parquet)
- Each column is stored separately
- Queries read only required columns
- Massive reduction in disk I/O
Two Important Query Terms
Projection
Columns required by the query.
select product, country, salesamount from sales;
Projection:
- product
- country
- salesamount
Predicate
Row-level filter condition.
select product, country, salesamount from sales where country='UK';
Predicate:
country = 'UK'
Parquet uses metadata to skip unnecessary data.
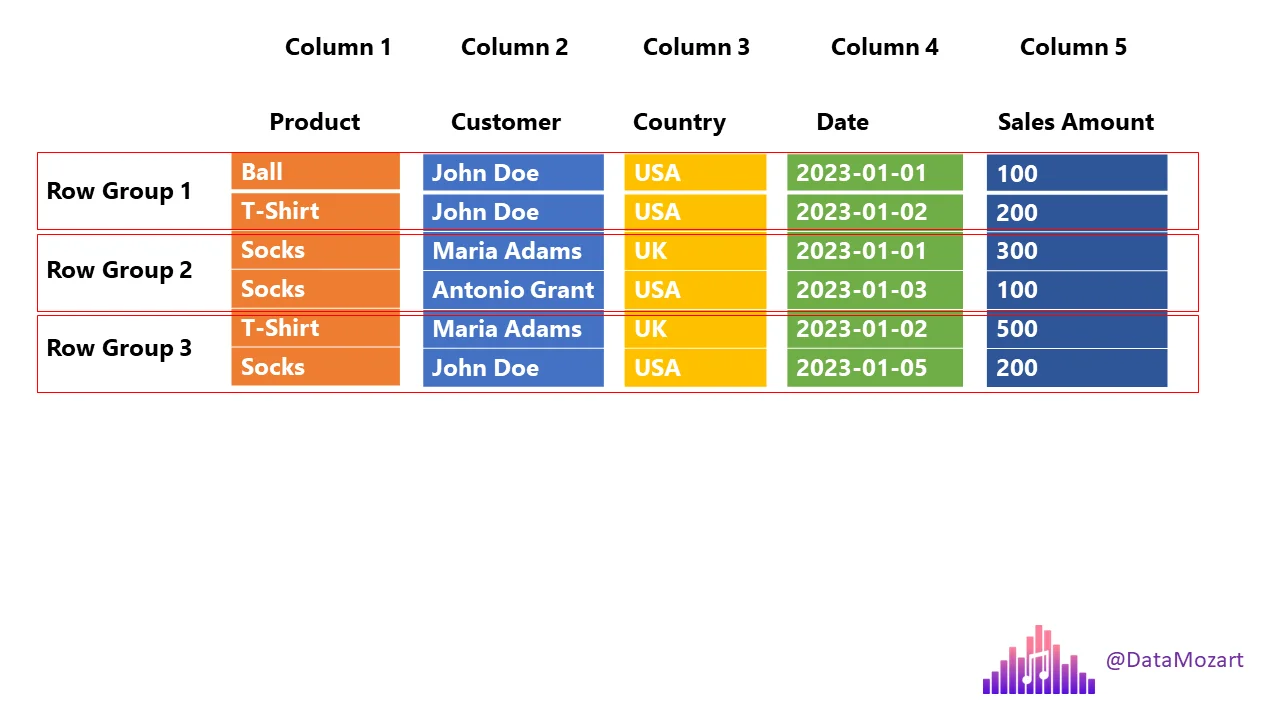
Row Groups
Parquet splits data into row groups.
Each row group contains:
- All columns
- Metadata (min/max values)
This allows:
- Parallel processing
- Skipping row groups that don’t match filters.
Parquet - Columnar Storage + Row Groups
Sample Data
| Product | Customer | Country | Date | Sales Amount |
|---|---|---|---|---|
| Ball | John Doe | USA | 2023-01-01 | 100 |
| T-Shirt | John Doe | USA | 2023-01-02 | 200 |
| Socks | Jane Doe | UK | 2023-01-03 | 150 |
| Socks | Jane Doe | UK | 2023-01-04 | 180 |
| T-Shirt | Alex | USA | 2023-01-05 | 120 |
| Socks | Alex | USA | 2023-01-06 | 220 |
Data stored inside Parquet
┌──────────────────────────────────────────────┐
│ File Header │
│ ┌────────────────────────────────────────┐ │
│ │ Magic Number: "PAR1" │ │
│ └────────────────────────────────────────┘ │
├──────────────────────────────────────────────┤
│ Row Group 1 │
│ ┌────────────────────────────────────────┐ │
│ │ Column Chunk: Product │ │
│ │ ├─ Page 1: Ball, T-Shirt, Socks │ │
│ └────────────────────────────────────────┘ │
│ ┌────────────────────────────────────────┐ │
│ │ Column Chunk: Customer │ │
│ │ ├─ Page 1: John Doe, John Doe, Jane Doe│ │
│ └────────────────────────────────────────┘ │
│ ┌────────────────────────────────────────┐ │
│ │ Column Chunk: Country │ │
│ │ ├─ Page 1: USA, USA, UK │ │
│ └────────────────────────────────────────┘ │
│ ┌────────────────────────────────────────┐ │
│ │ Column Chunk: Date │ │
│ │ ├─ Page 1: 2023-01-01, 2023-01-02, │ │
│ │ 2023-01-03 │ │
│ └────────────────────────────────────────┘ │
│ ┌────────────────────────────────────────┐ │
│ │ Column Chunk: Sales Amount │ │
│ │ ├─ Page 1: 100, 200, 150 │ │
│ └────────────────────────────────────────┘ │
│ ┌────────────────────────────────────────┐ │
│ │ Row Group Metadata │ │
│ │ ├─ Num Rows: 3 │ │
│ │ ├─ Min/Max per Column: │ │
│ │ • Product: Ball/T-Shirt/Socks │ │
│ │ • Customer: Jane Doe/John Doe │ │
│ │ • Country: UK/USA │ │
│ │ • Date: 2023-01-01 to 2023-01-03 │ │
│ │ • Sales Amount: 100 to 200 │ │
│ └────────────────────────────────────────┘ │
├──────────────────────────────────────────────┤
│ Row Group 2 │
│ ┌────────────────────────────────────────┐ │
│ │ Column Chunk: Product │ │
│ │ ├─ Page 1: Socks, T-Shirt, Socks │ │
│ └────────────────────────────────────────┘ │
│ ┌────────────────────────────────────────┐ │
│ │ Column Chunk: Customer │ │
│ │ ├─ Page 1: Jane Doe, Alex, Alex │ │
│ └────────────────────────────────────────┘ │
│ ┌────────────────────────────────────────┐ │
│ │ Column Chunk: Country │ │
│ │ ├─ Page 1: UK, USA, USA │ │
│ └────────────────────────────────────────┘ │
│ ┌────────────────────────────────────────┐ │
│ │ Column Chunk: Date │ │
│ │ ├─ Page 1: 2023-01-04, 2023-01-05, │ │
│ │ 2023-01-06 │ │
│ └────────────────────────────────────────┘ │
│ ┌────────────────────────────────────────┐ │
│ │ Column Chunk: Sales Amount │ │
│ │ ├─ Page 1: 180, 120, 220 │ │
│ └────────────────────────────────────────┘ │
│ ┌────────────────────────────────────────┐ │
│ │ Row Group Metadata │ │
│ │ ├─ Num Rows: 3 │ │
│ │ ├─ Min/Max per Column: │ │
│ │ • Product: Socks/T-Shirt │ │
│ │ • Customer: Alex/Jane Doe │ │
│ │ • Country: UK/USA │ │
│ │ • Date: 2023-01-04 to 2023-01-06 │ │
│ │ • Sales Amount: 120 to 220 │ │
│ └────────────────────────────────────────┘ │
├──────────────────────────────────────────────┤
│ File Metadata │
│ ┌────────────────────────────────────────┐ │
│ │ Schema: │ │
│ │ • Product: string │ │
│ │ • Customer: string │ │
│ │ • Country: string │ │
│ │ • Date: date │ │
│ │ • Sales Amount: double │ │
│ ├────────────────────────────────────────┤ │
│ │ Compression Codec: Snappy │ │
│ ├────────────────────────────────────────┤ │
│ │ Num Row Groups: 2 │ │
│ ├────────────────────────────────────────┤ │
│ │ Offsets to Row Groups │ │
│ │ • Row Group 1: offset 128 │ │
│ │ • Row Group 2: offset 1024 │ │
│ └────────────────────────────────────────┘ │
├──────────────────────────────────────────────┤
│ File Footer │
│ ┌────────────────────────────────────────┐ │
│ │ Offset to File Metadata: 2048 │ │
│ │ Magic Number: "PAR1" │ │
│ └────────────────────────────────────────┘ │
└──────────────────────────────────────────────┘
Example:
SELECT product, salesamount
FROM sales
WHERE country = 'UK';
Parquet will:
- Read only product, salesamount, country
- Skip row groups where country != UK
- Ignore all other columns
This is why Parquet is fast.
Compression
Parquet compresses per column, which works very well.
Common codecs:
Snappy
- Fast
- Low CPU usage
- Lower compression
- Used in hot / frequently queried data
GZip
- Slower
- Higher compression
- Used in cold / archival data
Encoding
Encoding reduces storage before compression.
Dictionary Encoding
- Replaces repeated values with small integers
- 0: Ball
- 1: T-Shirt
- 2: Socks
- Data Page: [0,1,2,2,1,2]
Run-Length Encoding
- Compresses repeated consecutive values
If Country column was sorted: [USA, USA, USA, UK, UK, UK]
RLE: [(3, USA), (3, UK)]
Delta Encoding
- Stores differences between values (dates, counters)
This makes Parquet compact and efficient.
Date column: [2023-01-01, 2023-01-02, 2023-01-03, ...]
Delta Encoding: [2023-01-01, +1, +1, +1, ...]
Summary about Parquet
- Columnar storage
- Very fast analytical queries
- Excellent compression
- Schema support
- Works across languages and engines
- Industry standard for data lakes
Python Example
import pandas as pd
file_path = 'https://raw.githubusercontent.com/gchandra10/filestorage/main/sales_100.csv'
# Read the CSV file
df = pd.read_csv(file_path)
# Display the first few rows of the DataFrame
print(df.head())
# Write DataFrame to a Parquet file
df.to_parquet('sample.parquet')
Some utilities to inspect Parquet files
WIN/MAC
https://aloneguid.github.io/parquet-dotnet/parquet-floor.html#installing
MAC
https://github.com/hangxie/parquet-tools
parquet-tools row-count sample.parquet
parquet-tools schema sample.parquet
parquet-tools cat sample.parquet
parquet-tools meta sample.parquet
Remote Files
parquet-tools row-count https://github.com/gchandra10/filestorage/raw/refs/heads/main/sales_onemillion.parquet